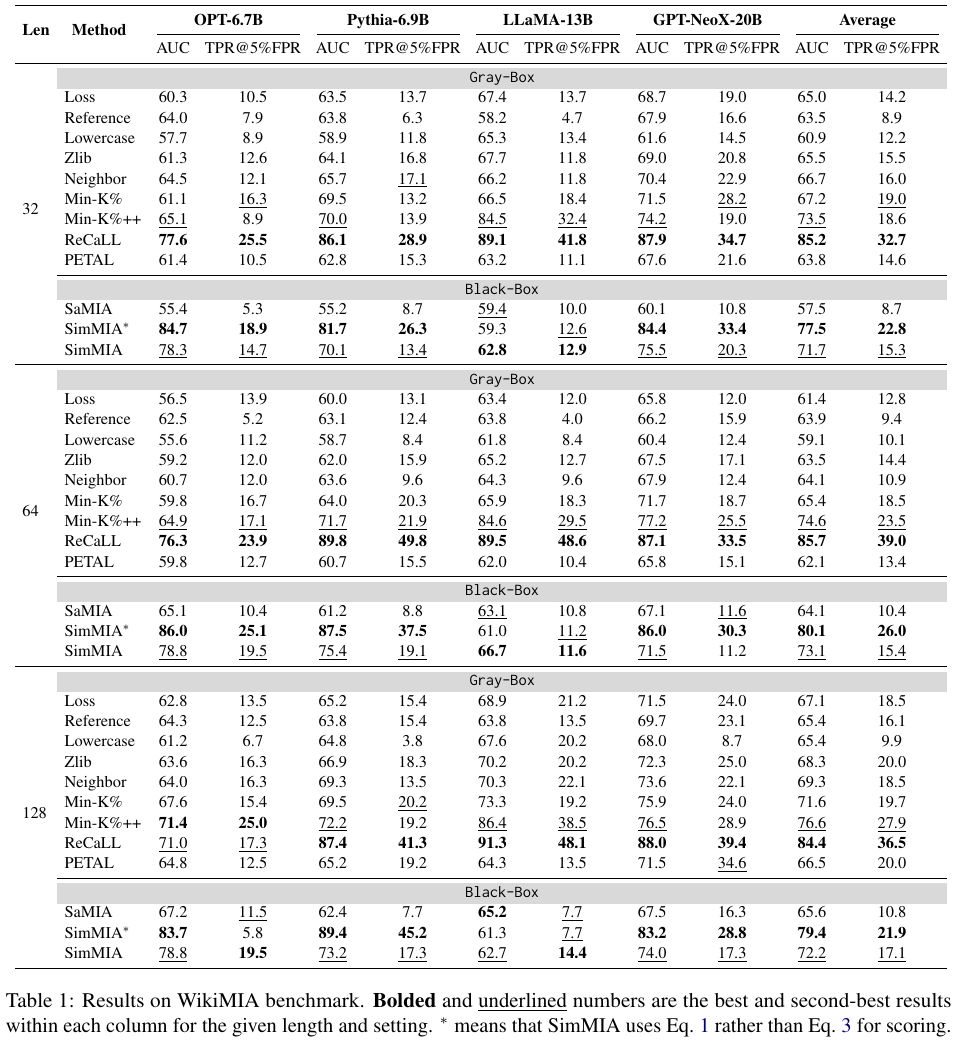
- WikiMIA: SimMIA achieves state-of-the-art black-box MIA, improving AUC by +16.6 over prior black-box baselines and even surpassing the best gray-box method on some models (e.g., OPT-6.7B)🥇.
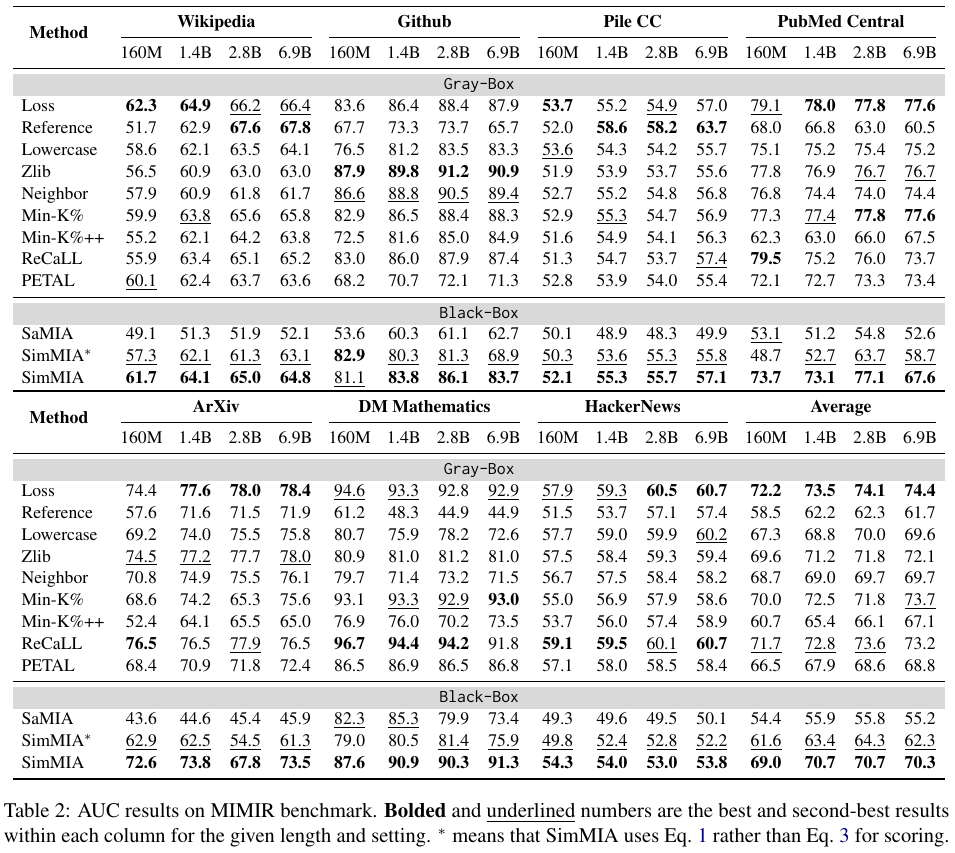
- MIMIR: SimMIA achieves +14.9 AUC over previous SOTA black-box performance, trailing the best gray-box methods by only 3.4 AUC points on average.
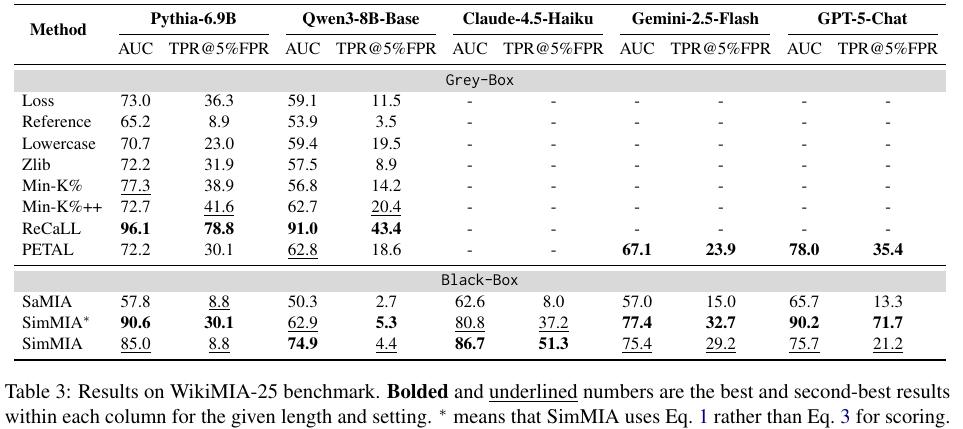
- WikiMIA-25: SimMIA generalizes to both legacy and latest (including proprietary) LLMs🚀, outperforming the best black-box baseline by +21.7 AUC and +25.8 TPR@5%FPR.
🗒️Abstract
Membership Inference Attacks (MIAs) act as a crucial auditing tool for the opaque training data of Large Language Models (LLMs). However, existing techniques predominantly rely on inaccessible model internals (e.g., logits) or suffer from poor generalization across domains in strict black-box settings where only generated text is available. In this work, we propose SimMIA, a robust MIA framework tailored for this text-only regime by leveraging an advanced sampling strategy and scoring mechanism. Furthermore, we present WikiMIA-25, a new benchmark curated to evaluate MIA performance on modern proprietary LLMs. Experiments demonstrate that SimMIA achieves state-of-the-art results in the black-box setting, rivaling baselines that exploit internal model information.
How SimMIA Works❓
SimMIA advances existing black-box MIAs on LLMs by:
- Word-by-word sampling: SimMIA samples the immediate next word for every possible prefix rather than a complete continuation for a fixed-length prefix.
- Semantic Scoring: SimMIA relies on soft embedding-based similarity to score each word rather than surface-form exact matching.
- Relative Aggregation: SimMIA computes the relative ratio between scores perturbed by non-members and unperturbed scores.
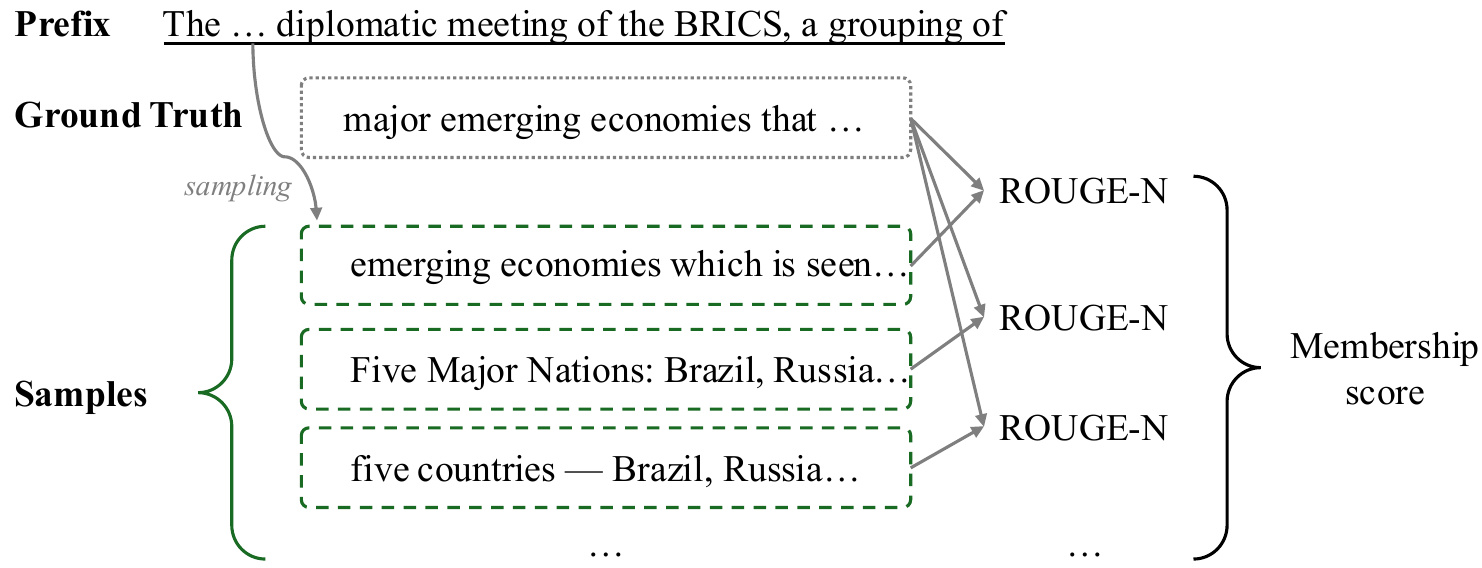
(a) SaMIA
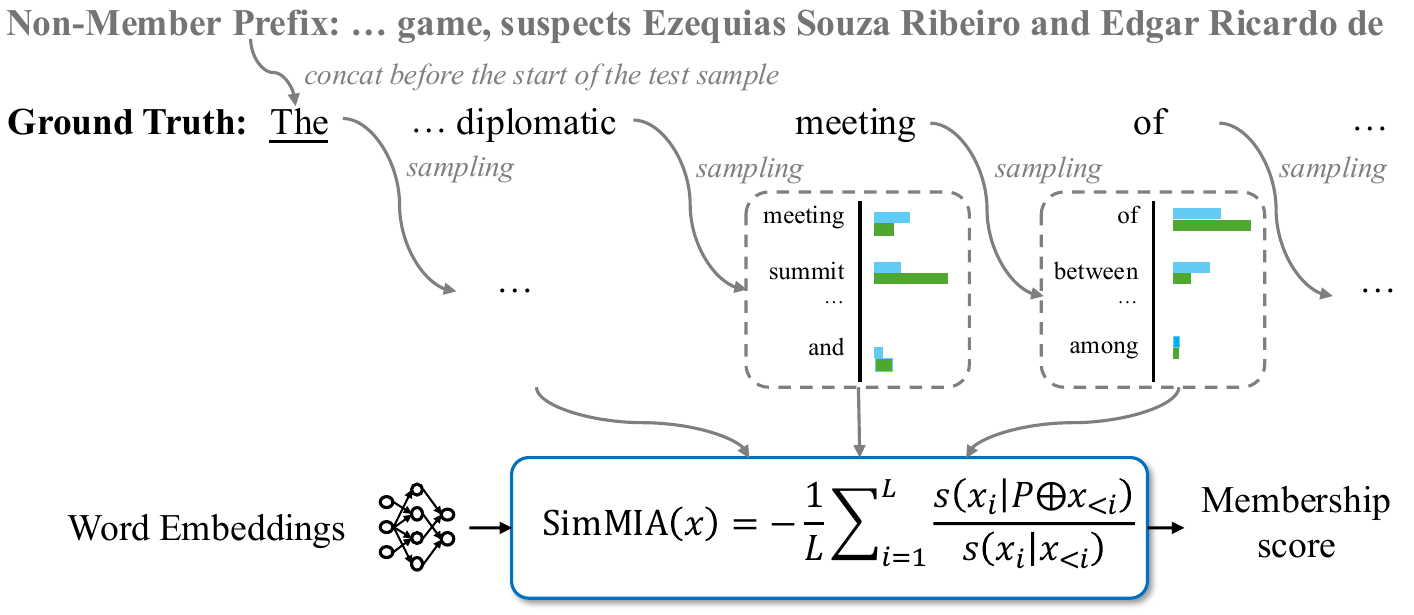
(b) SimMIA
Main Results🔝
We compare SimMIA with ten baselines in three benchmarks:
🌟 Citation
@misc{yi2026membershipinferencellmswild,
title={Membership Inference on LLMs in the Wild},
author={Jiatong Yi and Yanyang Li},
year={2026},
eprint={2601.11314},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.11314},
}